Introduction
Apache Kafka, one of the world’s most popular solutions for streaming massive amounts of data, continues to grow in popularity. At the recent NonStop TBC, Infrasoft saw this in sharp focus, with a number of customers and HPE NonStop partners talking to us about potential NonStop-Kafka use cases.
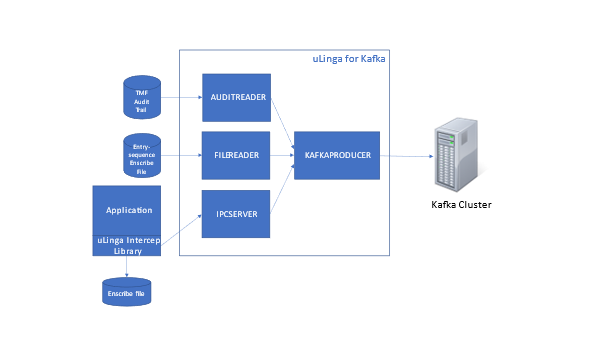
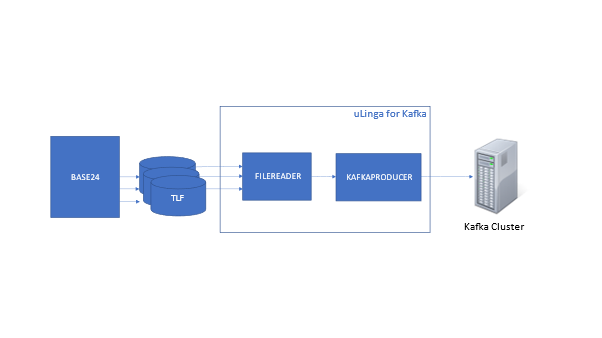
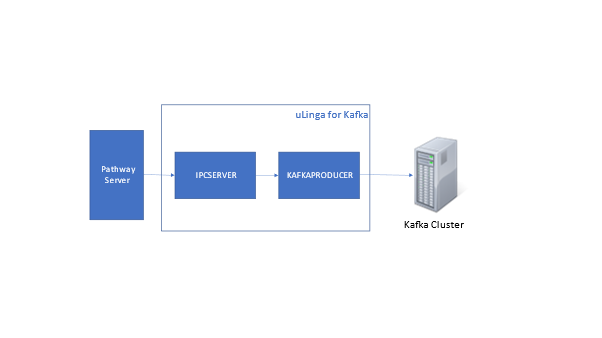
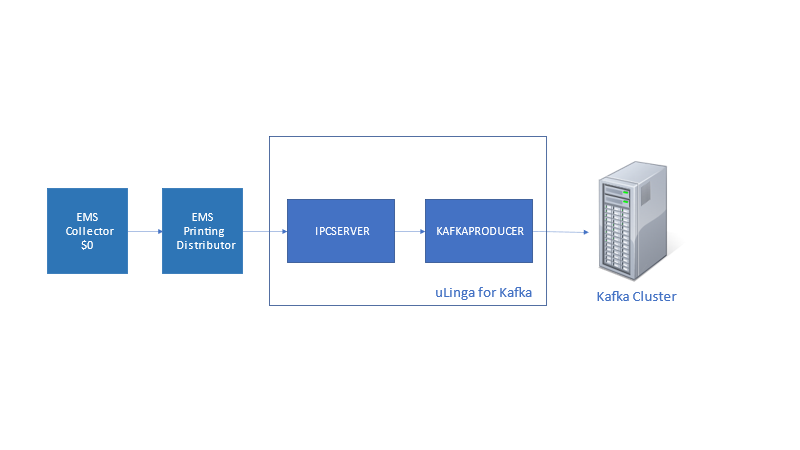
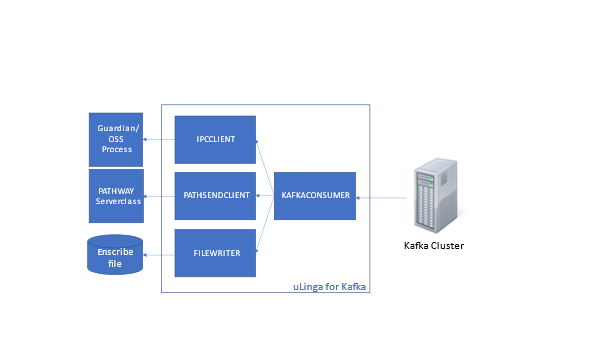
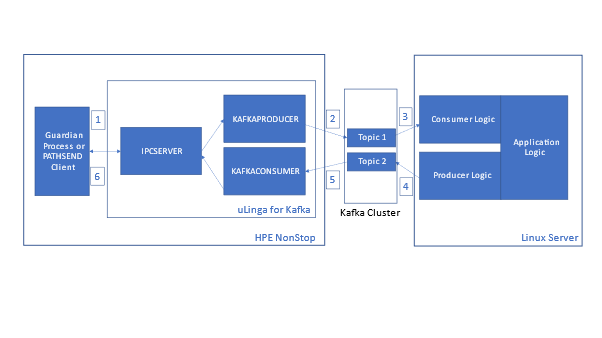
This article will give a summary of the capabilities, and potential use cases, for uLinga for Kafka – the best solution for integrating your HPE NonStop data and applications with Kafka.
Kafka usage continues to grow at pace – Kafka is now in use at more than 80% of the Fortune 100, and has big name users including Barclays, Goldman Sachs, Paypal, Square, Target, and others.1
But what is Kafka? From the Apache Kafka website: Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.2
Those sound a lot like environments where many HPE NonStop Servers also play a part, doesn’t it? Given that, it makes sense to have a good idea of how your NonStop applications and data can integrate with, and take advantage of, the capabilities of Kafka.
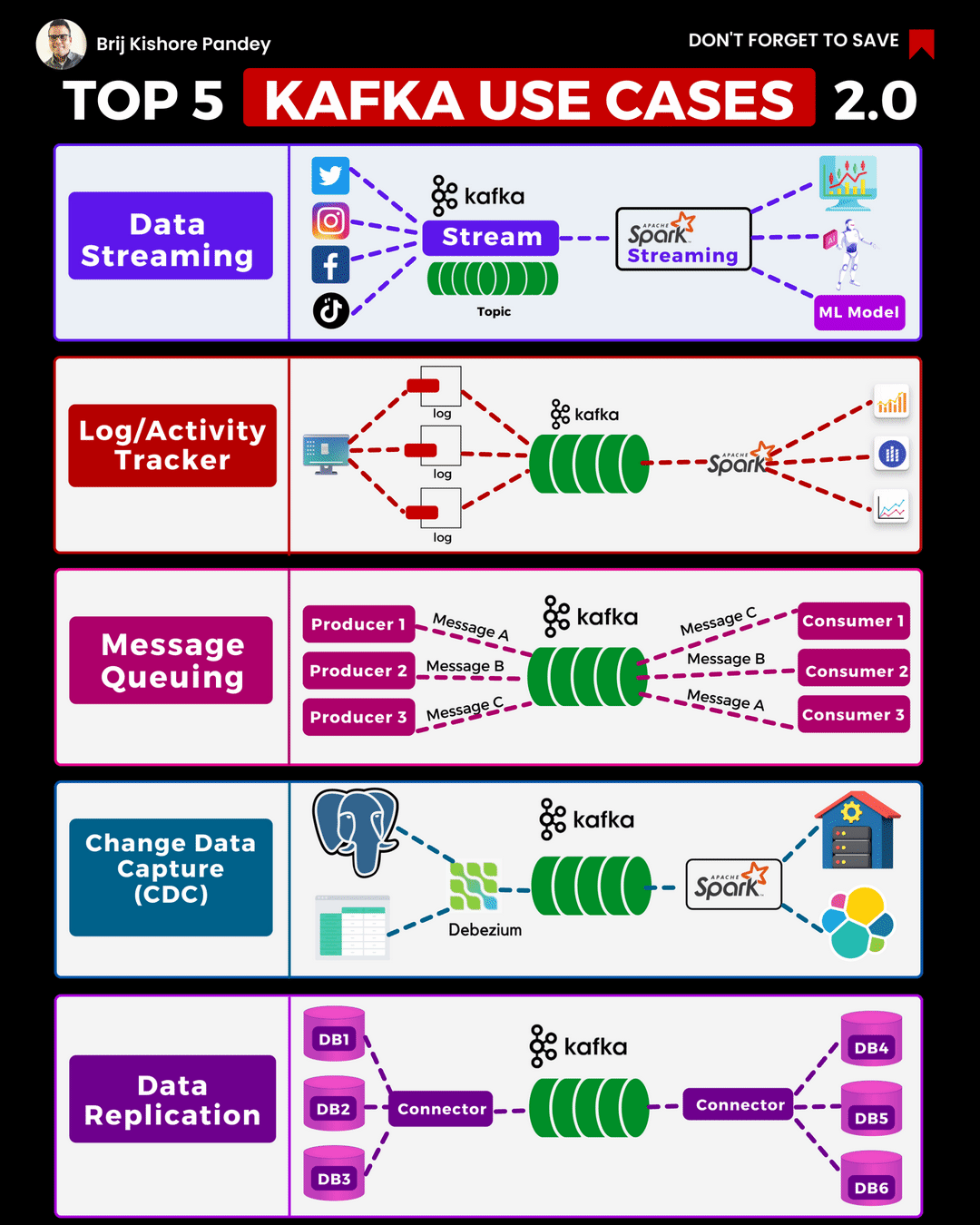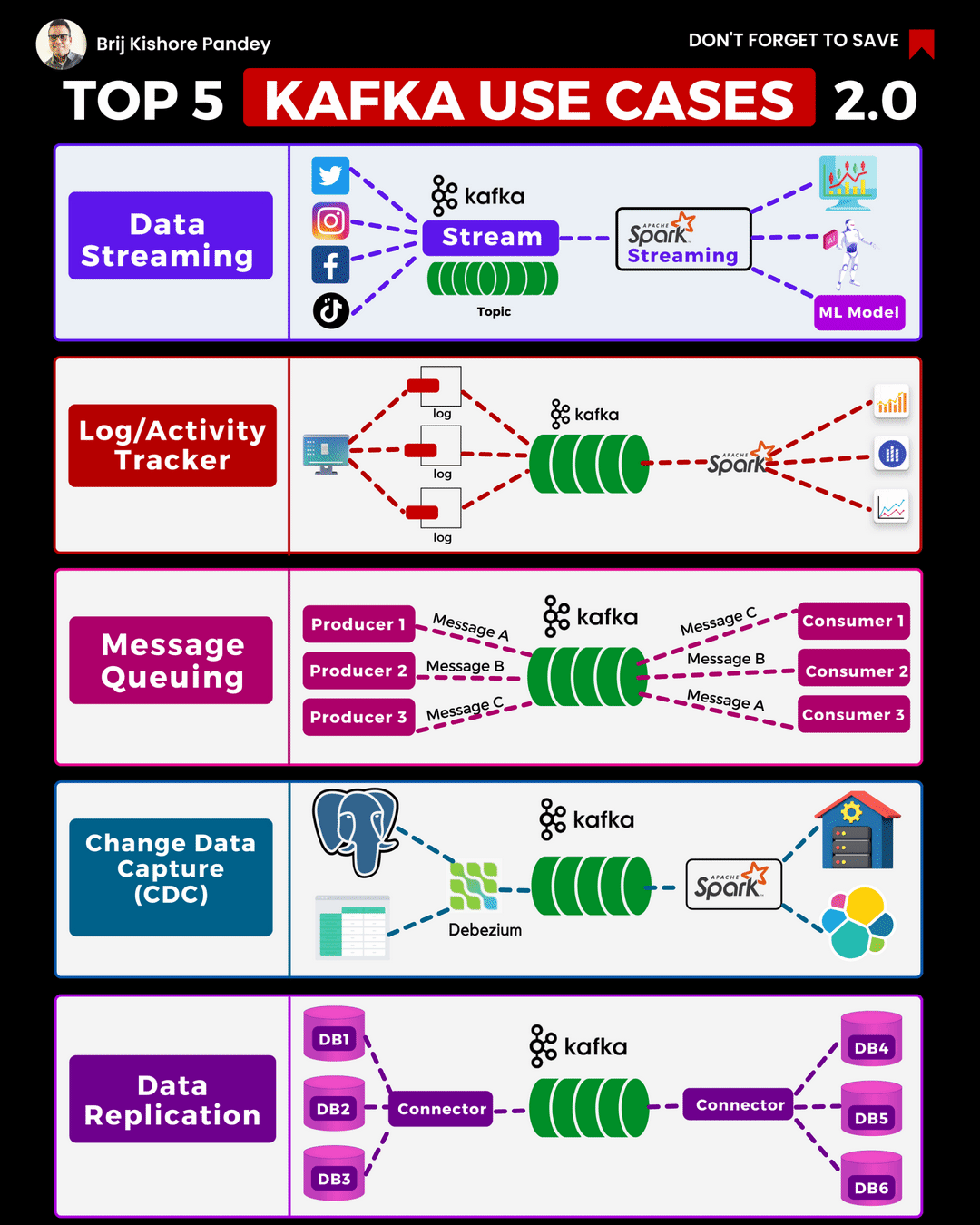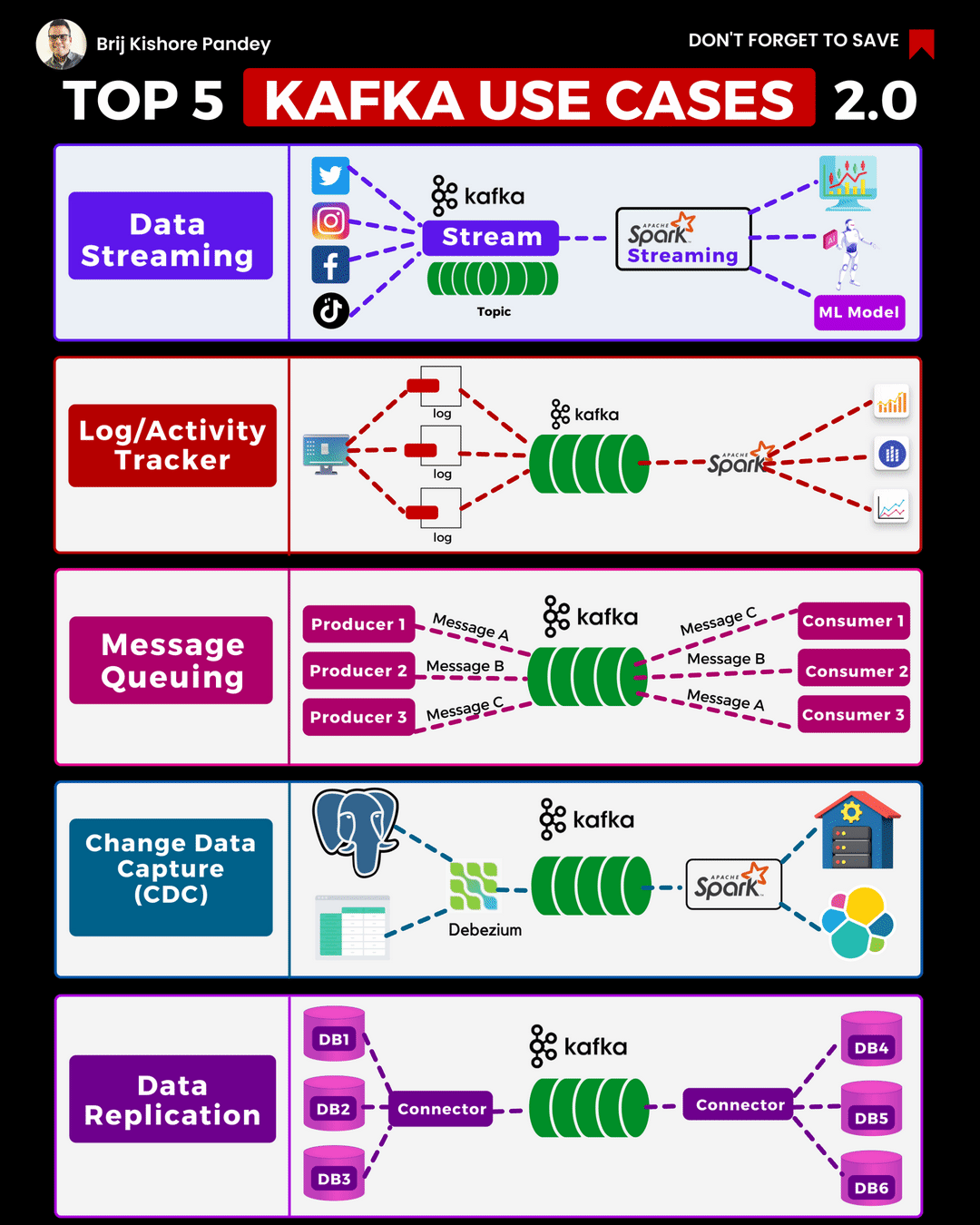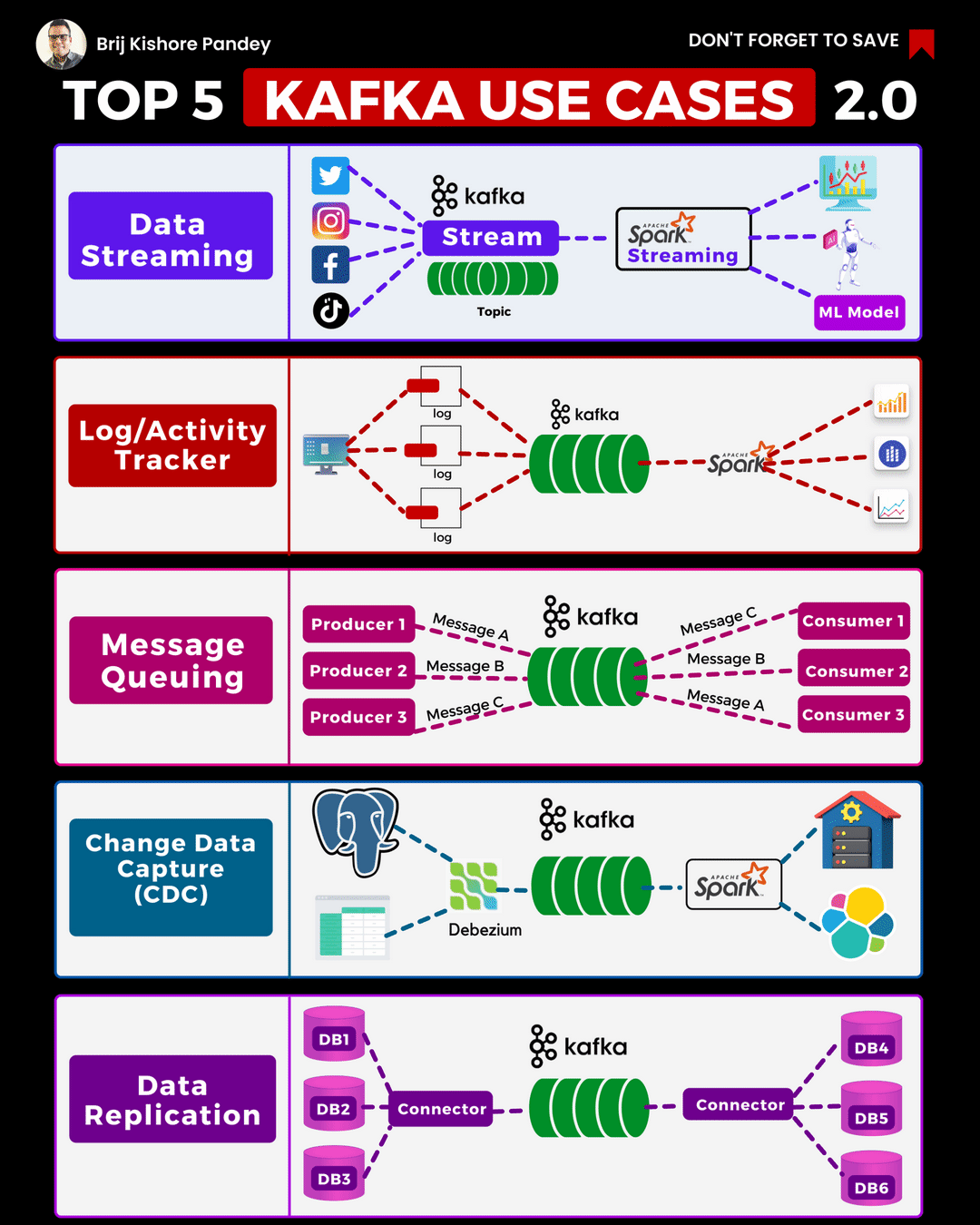
I recently came across this excellent animation on LinkedIn from Brij Kishore Pandey which shows the Top 5 current Kafka Use Cases. As these are relevant to NonStop users I thought it would be a good place to start, for this “Best of NonStop” edition of the Connection. In this article we will take a close look at the first 3 use cases in this animation.